Welcoming Yeti to the OSDFIR Infrastructure family
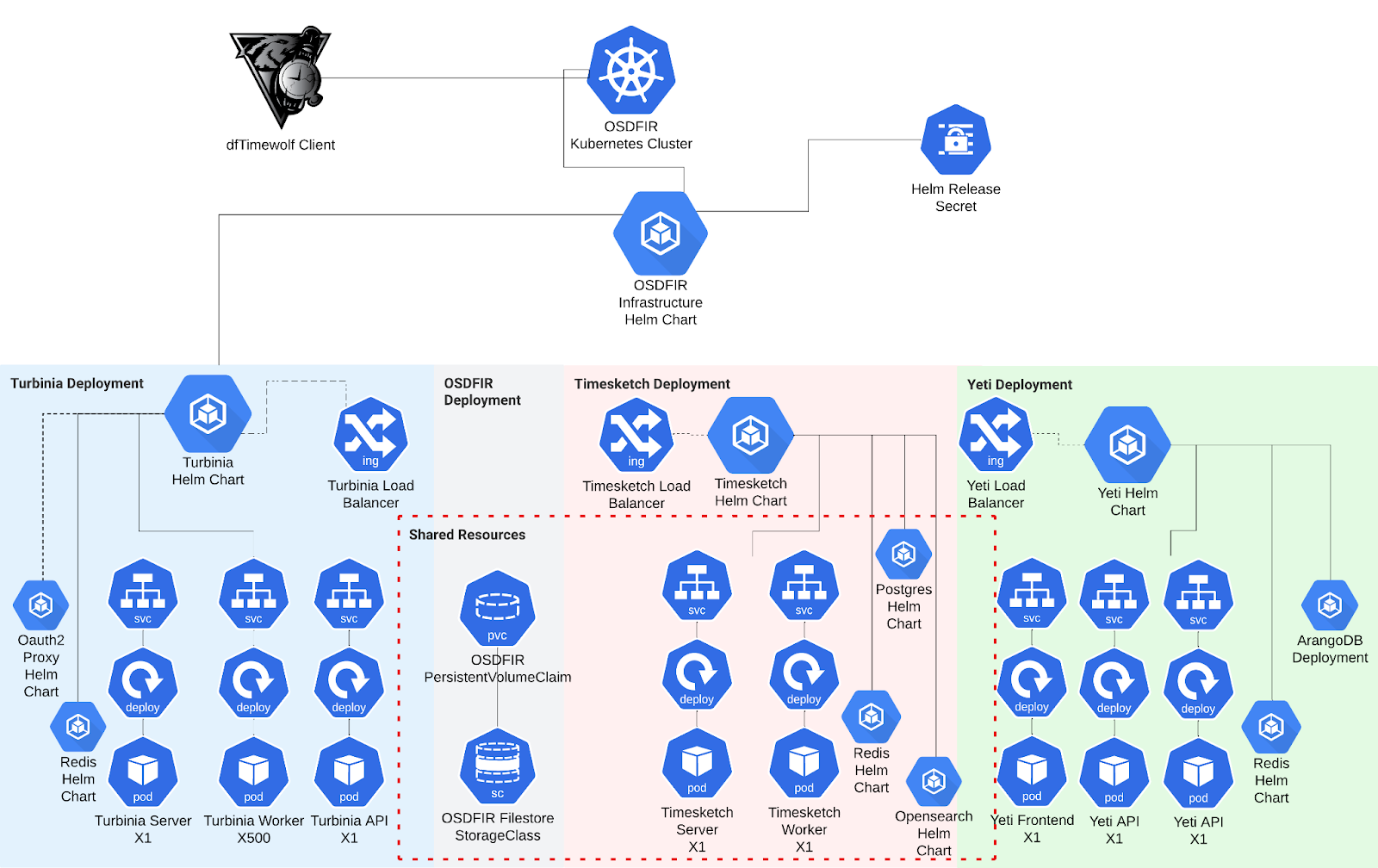
Authored by Thomas Chopitea and Wajih Yassine Overview We are excited to announce that Yeti is now available for use through the OSDFIR Infrastructure project. What is Yeti? Yeti aims to bridge the gap between Cyber Threat Intelligence (CTI) and Digital Forensics & Incident Response (DFIR) practitioners by providing a Forensics Intelligence platform and pipeline for DFIR teams. It was born out of the friction of having to repeatedly answer questions such as “where have I seen this artifact before?”, “how do I search for indicators of compromise (IOCs) related to this (or other) threats in my timeline?”, “what findings have I found useful in similar investigative scenarios?”. The main goal of Yeti is not only to collect IOCs and Techniques, Tactics, and Procedures (TTPs) like a classic threat intelligence platform, but to also store and deliver DFIR intelligence such as useful queries, artifact locations, and methodologies. How does Yeti integrate with the rest of the OS

